rnorm(10, 20, 2)¿Por qué utilizo datos simulados en mis cursos de Estadística?
¿Por qué utilizar datos simulados para enseñar conceptos estadísticos en Química Analítica?
Si ha seguido este blog se habrá percatado que en muchos de ellos he utilizado datos simulados para ejemplificar algún concepto estadístico.
Pero ¿por qué mejor no utilizar datos reales?
Por supuesto. No tendría sentido práctico para un(a) Químico(a) visualizar el concepto estadístico sólo con datos simulados, es necesario aplicarlo a datos reales con los “problemas” que esto conlleva:
- no normalidad
- contaminados con valores atípicos (outliers)
- asimétricos
- bimodales (cuando los datos analíticos fueron obtenidos usando 2 métodos distintos)
- heterocedásticos (a mayor concentración, mayor variabilidad)
- etc.
Sin embargo, los datos simulados tienen un objetivo en sí, pues permiten evaluar el desempeño del método estadístico bajo distintas condiciones, por ejemplo, repetibilidad versus reproducibilidad.
Simulación en lenaguaje R
Para ejemplificar la similación de datos analíticos, en este post utilizaremos el lenguaje de programación R el cual tiene incorporado todas las herramientas necesarias para simular datos de laboratorio. Si Ud. copia, pega y ejecuta el código en su laptop, obtendrá resultados levemente distintos, lo cual es lógico, pues son datos simulados y todas las simulaciones son distintas y aleatorias
Ojo con la simulacion de datos en Excel, porque a veces éste genera los mismos datos “aleatorios”
Vamos ejemplificar cómo simular datos normales con R:
Para generar los datos normales utilizaremos la función rnorm() . Esta función tiene 3 argumentos:
rnorm = random normal
nes el número de datos aleatorios que simularemosmeanes la media teórica de esa distribución normalsdes la desviación teórica de esa distribución normal
Por lo tanto, si en R utilizamos la función rnorm(n = 10, mean = 20, sd = 2) estamos simulando n = 10 datos normales con media 20 y desviación estándar 2. Habitualmente se omiten los nombres de los argumentos, siempre y cuando los ingrese en ese orden, por ejemplo: rnorm(10, 20, 2).
Entonces, abra un script nuevo en RStudio y gúardelo con un nombre , copie y pegue el siguiente código:
Aquí están las instrucciones para hacer esto
Seleccióne esa línea de código con el mouse y presione el botón Run (o las teclas Ctr + Enter).
En la consola, Ud. debiera visualizar 10 datos:
[1] 18.87905 19.53965 23.11742 20.14102 20.25858 23.43013 20.92183 17.46988
[9] 18.62629 19.10868Para poder utilizar eficientemente los datos simulados debemos guardarlos con un nombre en R.
Por ejemplo, generemos \(n = 100\) datos que efectivamente provienen de una distribución normal cuya media es 50 y la desviación estándar es 5. Guardaremos los datos en R con el nombre datos.simulados:
set.seed(123)
datos.simulados <- rnorm(100, 50, 5)Ahora, en la consola de RStudio escriba datos.simulados y visualizará SUS datos (recuerde que serán distintos a los míos):
datos.simulados [1] 47.19762 48.84911 57.79354 50.35254 50.64644 58.57532 52.30458 43.67469
[9] 46.56574 47.77169 56.12041 51.79907 52.00386 50.55341 47.22079 58.93457
[17] 52.48925 40.16691 53.50678 47.63604 44.66088 48.91013 44.86998 46.35554
[25] 46.87480 41.56653 54.18894 50.76687 44.30932 56.26907 52.13232 48.52464
[33] 54.47563 54.39067 54.10791 53.44320 52.76959 49.69044 48.47019 48.09764
[41] 46.52647 48.96041 43.67302 60.84478 56.03981 44.38446 47.98558 47.66672
[49] 53.89983 49.58315 51.26659 49.85727 49.78565 56.84301 48.87115 57.58235
[57] 42.25624 52.92307 50.61927 51.07971 51.89820 47.48838 48.33396 44.90712
[65] 44.64104 51.51764 52.24105 50.26502 54.61134 60.25042 47.54484 38.45416
[73] 55.02869 46.45400 46.55996 55.12786 48.57613 43.89641 50.90652 49.30554
[81] 50.02882 51.92640 48.14670 53.22188 48.89757 51.65891 55.48420 52.17591
[89] 48.37034 55.74404 54.96752 52.74198 51.19366 46.86047 56.80326 46.99870
[97] 60.93666 57.66305 48.82150 44.86790¿Cómo sé si la simulación generó 50 datos simulados con media 50 y desviación estándar 5?
Hagamos lo que siempre debe hacer antes de llevar a cabo cualquier test estadístico: Un EDA, o sea, un Análisis Exploratorio de Datos (Exploratory Data Analysis):
Utilizaremos algunas funciones básicas de R para hacer gráficos. Podríamos utilizar la potente librería ggplot2 pero para ir al punto rápidamente, por esta vez, sólo utilizaremos las funciones por defecto de R (base).
La herramienta gráfica por excelencia para evaluar si el modelo normal es “razonable” para un conjunto de datos es el QQ-Plot de normalidad . En R lo obtiene con los siguientes comandos:
En los cursos que dicto en Analytical discutimos en profundidad las pruebas de normalidad y cómo se interpretan
qqnorm(datos.simulados)
qqline(datos.simulados)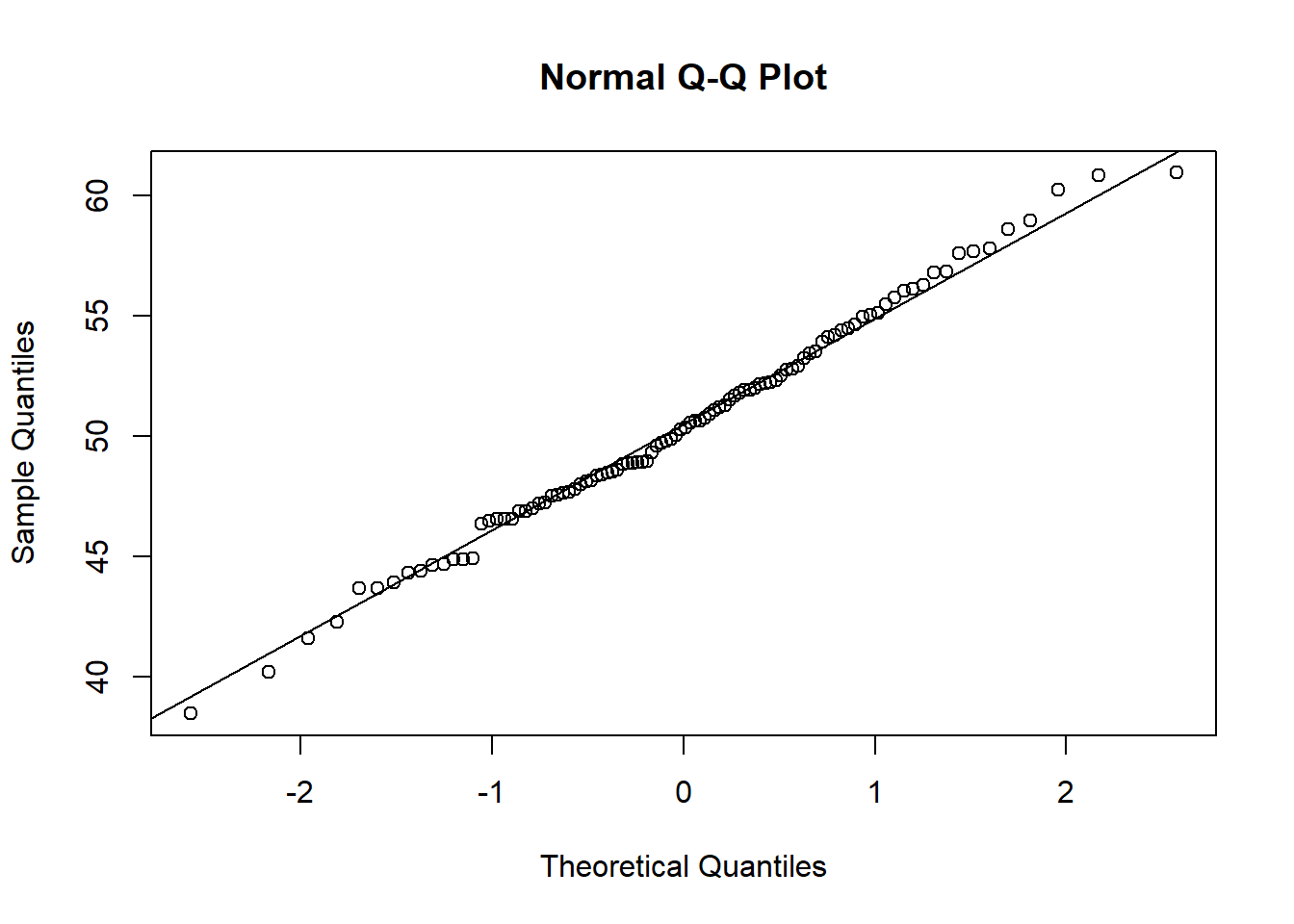
Al observar este QQ-Plot (que será distinto al suyo) podemos apreciar que la simulación de datos normales fue la esperada. El QQ-plot es casi de libro y muestra que el modelo Normal es “adecuado” o “razonable” para modelar nuestros datos. Obvio, si fueron simulados normales.
Si se fija la mayoría de los datos yacen sobre una línea dibujada. Algunos, aquellos ubicados en los extremos, se desvían de la línea, lo cual es esperado.
¿Será cierto que la media de los datos simulados es 50 y la desviación estándar 5? Usemos los comandos mean() y sd() para obtener el promedio y la desviación estándar, respectivamente:
mean(datos.simulados)[1] 50.45203sd(datos.simulados)[1] 4.564079¿Cómo? ¿qué sucedió? ¿Por qué no obtuvimos una promedio de exactamente 50 y una desviación estándar de 5?
Porque, básicamente, lo que estamos haciendo es “muestrear” un universo de datos que tienen una distribución normal con media 50 y desviación estándar 5, pero que debido al muestreo finito (n = 50) existirá una aleatoriedad. Los datos muestreados se asemejarán a la distribución original, pero no serán exactamente como esperaríamos teóricamente. Observe el histograma de los \(N = 50\) datos simulados:
hist(datos.simulados)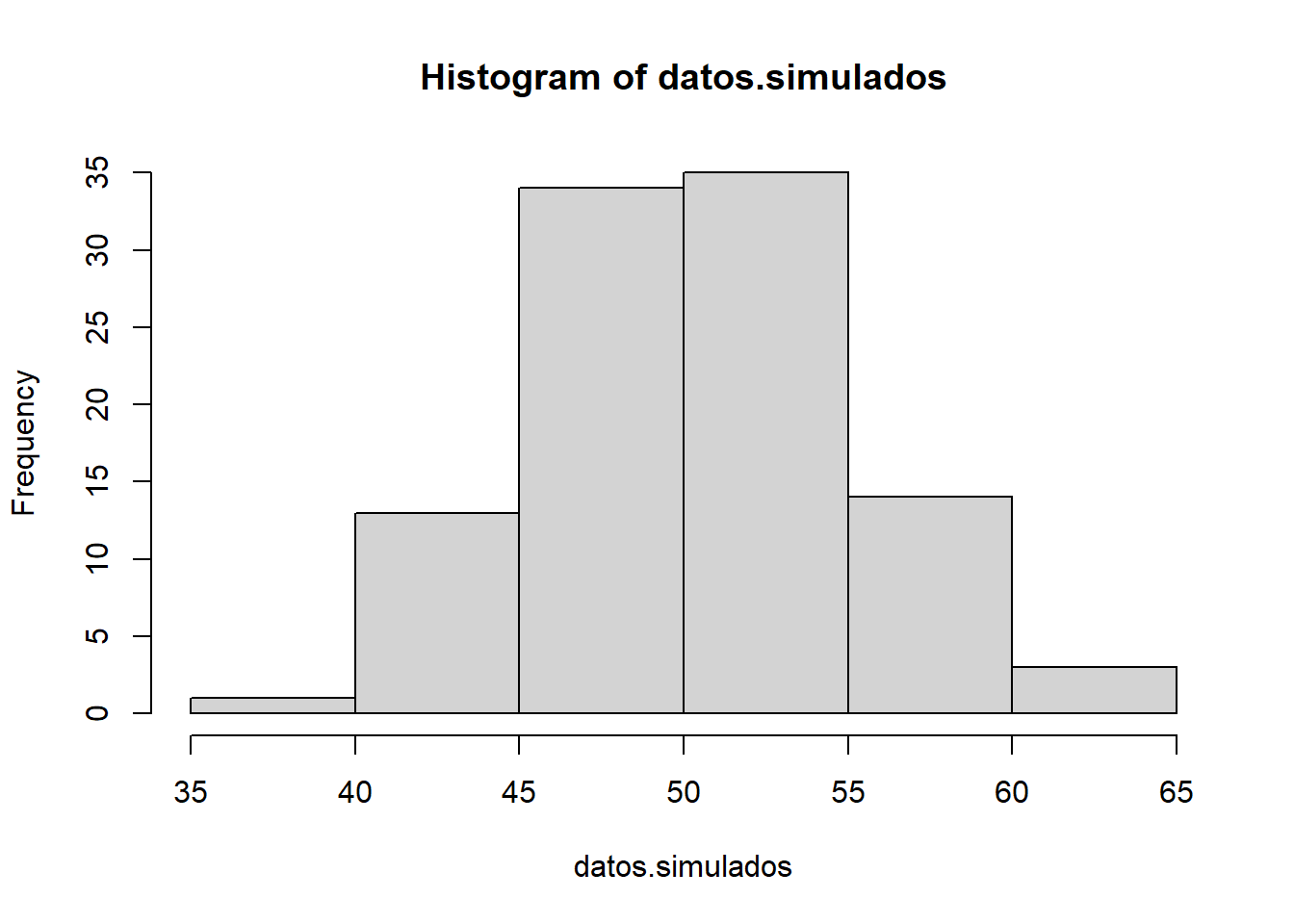
Efectivamente, la muestra de \(N = 50\) datos se asemeja a la distribución normal de la cual fueron obtenidos, pero no es exactamete lo que la teoría esperaría. Veamos qué sucede si aumentamos el \(N\) en la simulación a n = 10000:
Note que hemos sobreescrito el vector de
datos.simuladosdatos.simulados <- rnorm(10000, 50, 5)
hist(datos.simulados, main = 'Histograma de datos simulados')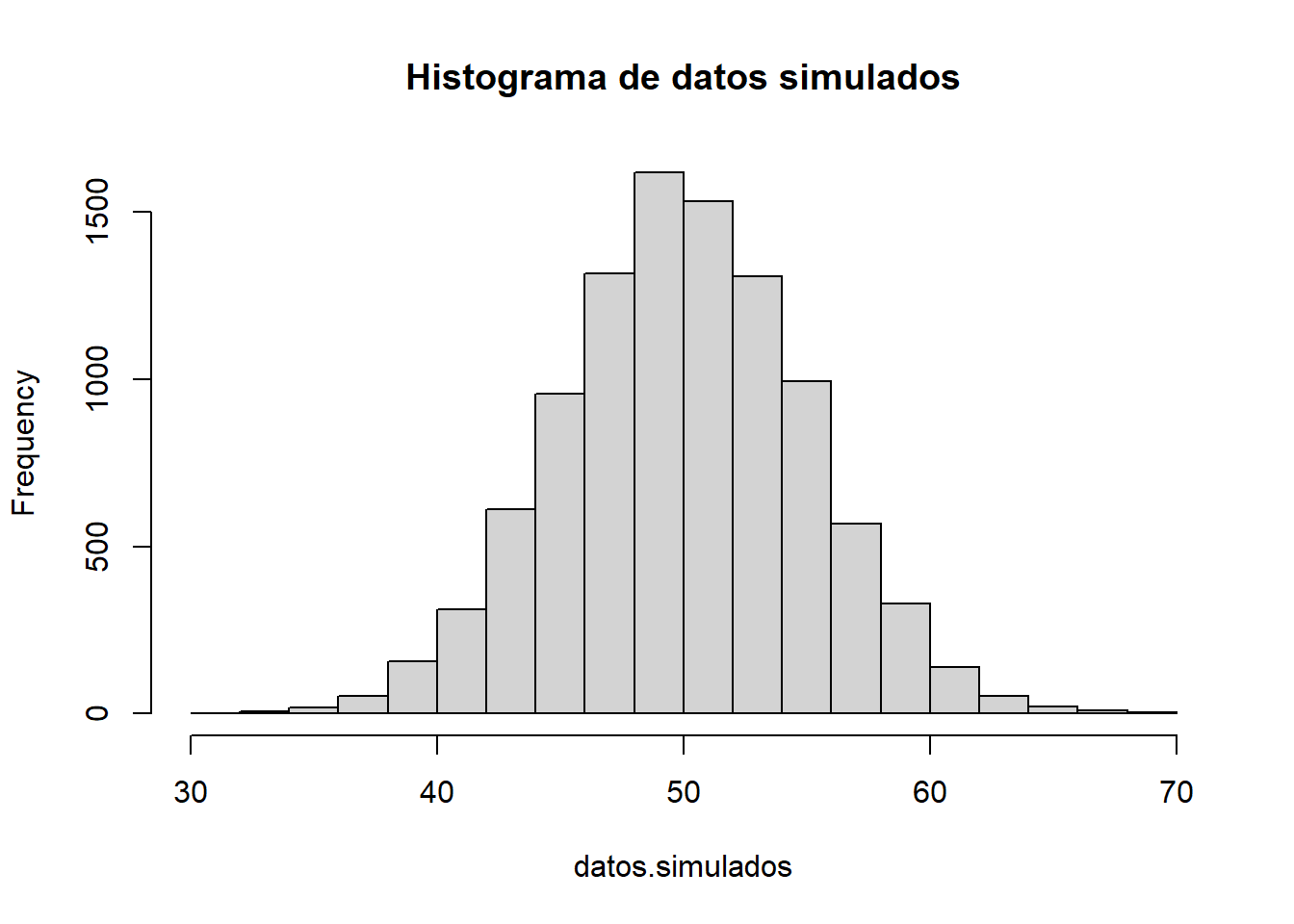
Ahora se asemeja mucho más a lo que esperaríamos de una distribución Normal. De hecho, observe el promedio y la desviación estándar:
mean(datos.simulados)[1] 49.98414sd(datos.simulados)[1] 4.996275Al aumentar el \(N\) estos estimadores se aproximan a los valores que simulamos teóricamente. ¿Qué sucedería si \(N\) fuese muy grande?
¿Se acuerda de la frase “cuando \(N \rightarrow \infty\)”?
Correcto: El promedio y la desviación estándar muestral convergen a los “verdaderos” valores de media y desviación estándar.
¿Cómo se interpreta una simulación desde el punto de vista químico analítico?
Lo que hemos hecho hasta ahora con una simulación es replicar lo mismo que Ud. hace en su laboratorio, es decir, analizar \(N\) alícuotas de una misma muestra en forma independiente y en condiciones de repetibilidad: mismo analista, mismo instrumento y en un corto intervalo de tiempo.
Lo de condiciones de repetibilidad es una suposición. No necesariamente tiene que ser así
La única gran diferencia, es que ahora conocemos tres cosas de antemano cuando hacemos una simulación:
- La “verdadera” media de los valores de concentración de la muestra al aplicar ese método analítico en particular
- La dispersión esperada/teórica de las condiciones de análisis (en este caso, asumimos repetibilidad)
- La “veradera” distribución de los datos analíticos
Por lo tanto, cuando generamos \(N = 3\) datos normales con media 100 mg/kg y desviación estándar 3 mg/kg estamos asumiendo varias cosas, por ejemplo:
rnorm(n = 3, mean = 100, sd = 3)- que en el laboratorio hemos analizado una misma muestra en triplicado
- que el mecanismo generador de datos analíticos puede ser modelado mediante una distribución Normal con media = 100 y desviación estándar = 3. Es un modelo teórico, esos valores no son conocidos por el analista.
Note que no hemos afirmado en esta simulación que la verdadera concentración de la muestra es 100 mg/kg. Lo que hemos dicho, es que la verdadera media de la concentración cuando aplicamos ese método analítico en particular es 100 mg/kg.
No hemos dicho que 100 mg/kg es la verdadera concentración de la muestra
¿Por qué no es lo mismo?
Porque no hemos considerado el sesgo del método analítico. Si éste no tuviera sesgo, entonces, la media de la distribución Normal coincidiría con la concentración verdadera de la muestra. Pero eso, en el laboratorio, nunca lo podremos saber.
¿Por qué he puesto en cursiva la palabra *verdadera¨**?
Porque cuando hemos hecho la simulación conocemos de antemano la media y la desviación estádar del proceso analítico. Obviamente, en el laboratorio el o la analista no conoce esos valores. De hecho nadie los conoce. Lo que ocurre en el laboratorio es que el analista obtiene \(N\) resultados analíticos de la misma muestra y calcula una estimación de la media y desviación estándar de esos valores que no conoce, a través del promedio y la desviación estándar de esos \(N\) replicados.
Lo que obtiene el analista son estimadores de la verdadera media y la verdadera desviación estándar del proceso analítico. Esos valores, en el laboratorio, son desconocidos. Sólo podemos obtener estimadores.
Ejemplo
La concentración verdadera de tetracilina en una muestra de salmón es 95 mg/kg. El laboratorio ha validado el método de análsis por SPE/HPLC-DAD. La repetibilidad del método analítico es 10 mg/kg.
Generar una simulación del análisis de una misma muestra en triplicado, en condiciones de repetibilidad.
- Asuma que los datos pueden ser modelados con una distribución Normal.
- Asuma que el método analítico no tiene sesgo.
En este ejemplo podemos generar la simulación a través del siguiente código en R:
simulacion <- rnorm(n = 3, mean = 95, sd = 10)Veamos qué tal anduvo el “análisis” de la muestra.
simulacion[1] 89.39524 92.69823 110.58708Mmm… Anduvo “bastante bien”: 89, 92 y 110 mg/kg
Calculemos el promedio y la desviación estándar de esos triplicados:
mean(simulacion)[1] 97.56018sd(simulacion)[1] 11.40186El promedio 97.6 mg/kg está “cerca” de la verdadera concentración de la muestra que es 95 mg/kg. Lo mismo ocurre con la desviación estándar de los triplicados 11.4 mg/kg.
El laboratorio informará al cliente que ha obtenido una concentración de tetraciclina en esa muestra de salmón de 97.6 mg/kg. Sin embargo, la verdadera concentración de esa muestra es 95 mg/kg
Obviamente, en el laboratorio Ud. no sabe que la concentración es 95 mg/kg. Ud. simplemente ejecuta el análisis, obtiene un valor promedio e informa.
¿Acaso no dijimos que el método no tenía sesgo?
Aunque su método analítico fuese perfecto y no tuviera sesgo, siempre existirá una diferencia entre el valor promedio de sus replicados y la verdadera concentración de la muestra.
¿Y eso es grave? Depende.
¿Para su cliente una diferencia de \(\Delta = 2.6\) mg/kg es importante para ese nivel de concentración?
Esta diferencia encontrada no es sesgo analítico. En esta simulación, es una diferencia que refleja la aleatoriedad del análisis químico. No es un problema químico o del método, es el reflejo de la incertidumbre de medición.
El problema es que Ud. en el laboratorio no lo sabe (ni lo sabrá nunca).
Ahora, veamos una situación más real en el laboratorio.
¿Qué sucedería si repitiéramos el análisis del triplicados muchas veces?
ES decir, que el analista analice \(N = 3\) alícuotas independientes en condiciones de repetibilidad y cada vez informe el promedio. Simulemos ese proceso 1000 veces. Guardaremos esos 1000 promedios (de triplicados) con el nombre promedios.triplicados:
Utilizamos la función
replicate() para simular 1000 veces el proceso de analizar triplicados de la misma muestra e informar el promediopromedios.trplicados <- replicate(1000, mean(rnorm(n = 3, mean = 95, sd = 10)))Ok. Ahora analicemos esos 1000 promedios.
hist(promedios.trplicados, main = "Histograma de los 1000 promedios")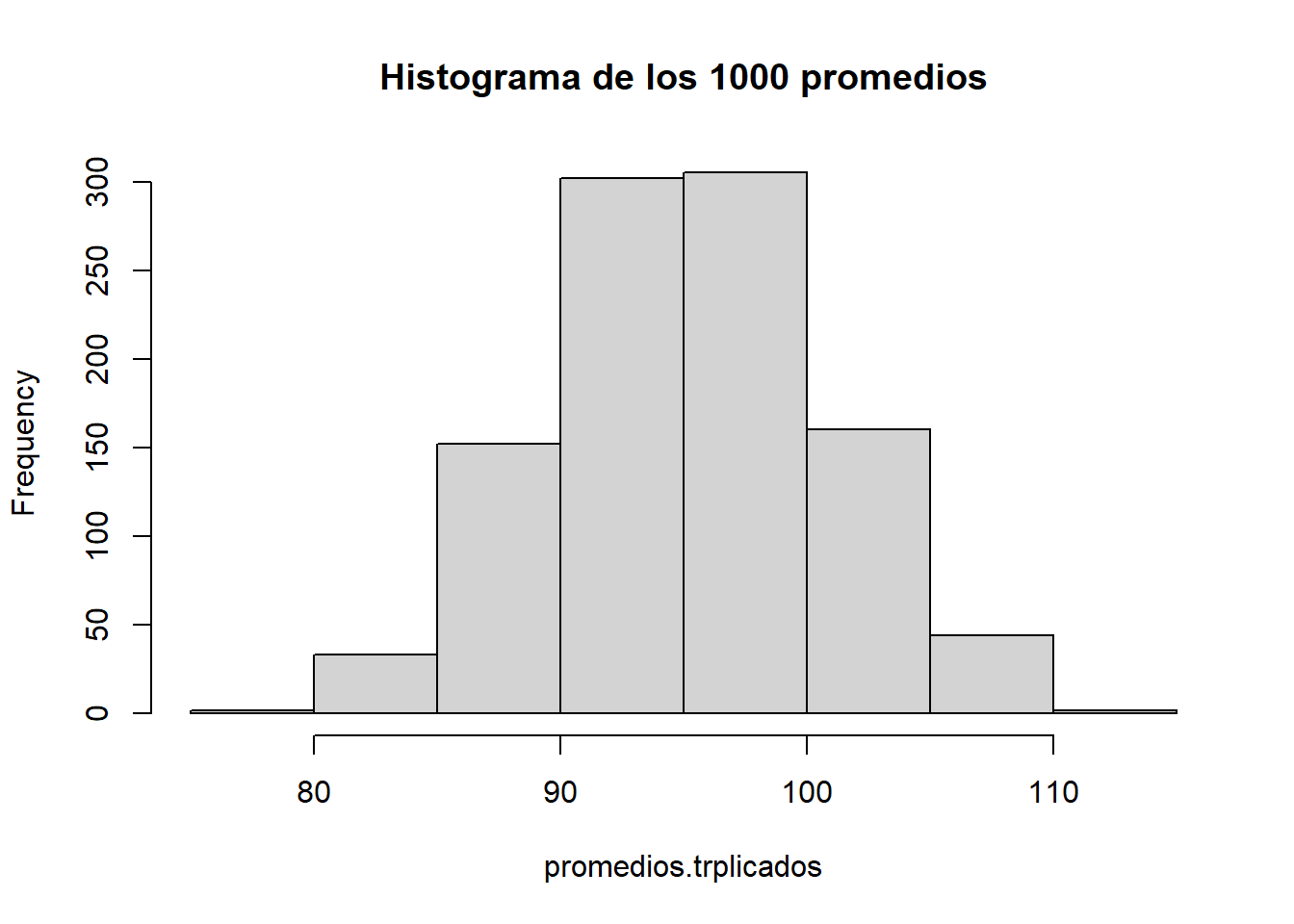
Interesante, se observa la forma acampanada de una Normal. Confirmemos este hallazgo con un gráfico de QQ-Plot de normalidad:
qqnorm(promedios.trplicados)
qqline(promedios.trplicados)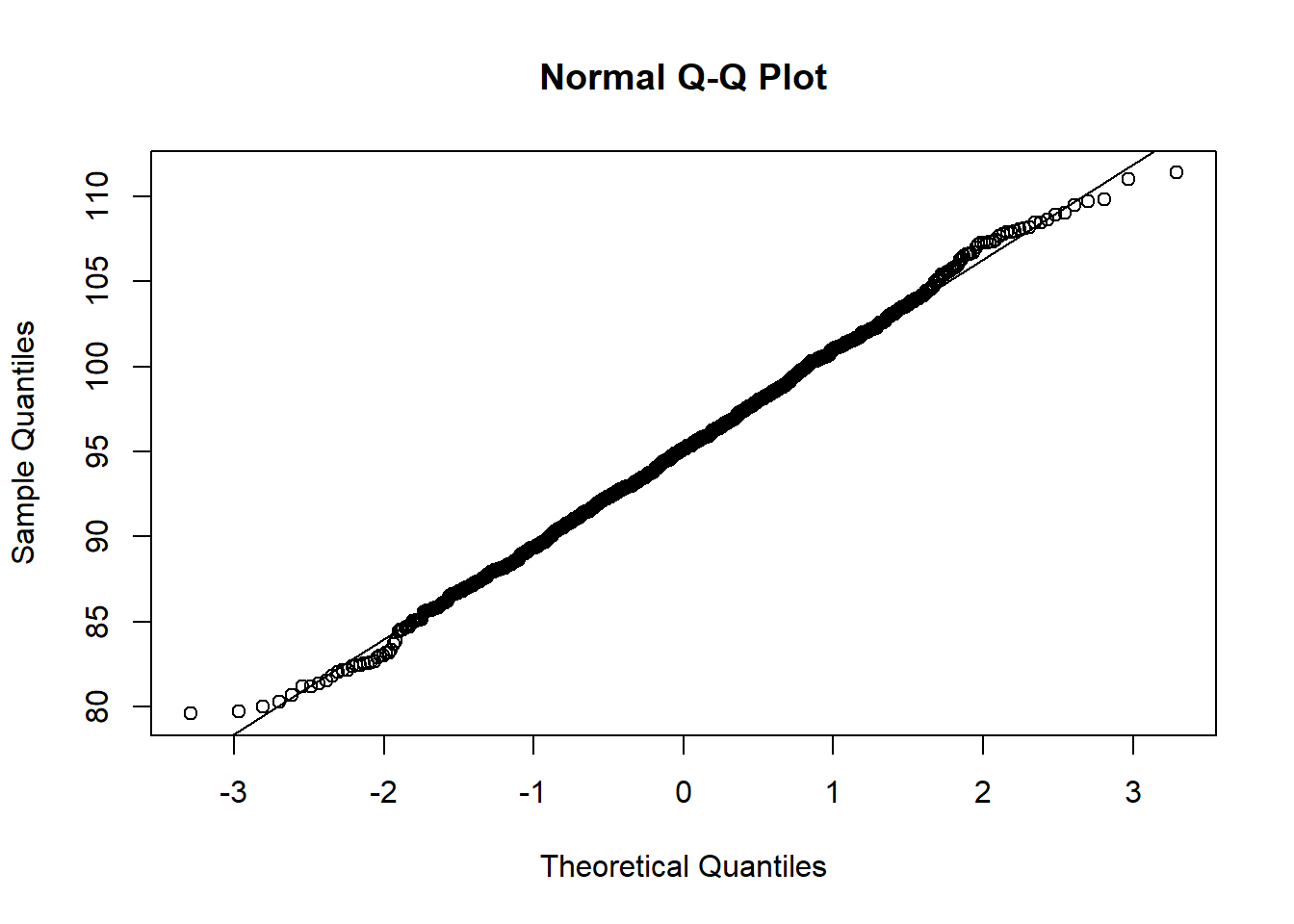
Perfecto. Es lo que esperábamos. Si Ud. recuerda el Teorema Central del Límite, éste nos dice que no importa la distribución original de los datos, los promedios tienden a la Normalidad a medida que aumenta el tamaño de la muestra.
Observe, ahora, el promedio y la desviación estándar de esos 1000 promedios:
mean(promedios.trplicados)[1] 95.12827sd(promedios.trplicados)[1] 5.705575El promedio de los 1000 promedios 95.1 mg/kg c onverge al valor teórico de 95 mg/kg. ¿Pero qué sucedió con la desviación estándar?¿no habíamos simulado que fuese 10 mg/kg? ¿por qué obtuvimos 5.7 mg/kg?
¿Recuerda el error estándar del promedio \(SE_{\overline{x}}\)?
\[SE_{\overline{x}} = \frac{\sigma}{\sqrt{N}}\] donde \(\sigma\) es la desviación estándar de los datos originales (antes de calcular el promedio de cada triplicado) y \(N\) es el número de replicados de la muestra problema (en este ejemplo, \(N = 3\)).
Si Ud. realizó 1000 veces la simulación de llevar a cabo análisis en triplicado de la misma muestra, y en cada vez obtuvo el promedio de los trplicados, entonces la desviación estándar de esos 1000 promedios es el \(SE_{\overline{x}}\). En este caso, en que conocemos de antemano la desviación estándar de los datos \(\sigma = 10\) mg/kg, el \(SE_{\overline{x}}\) es:
\[SE_{\overline{x}} = \frac{\sigma}{\sqrt{N}} = \frac{10}{\sqrt{3}} = 5.8\]
Por lo tanto, la simulación resultó perfecta. Se cumplió todo lo que la teoría predecía.
Para poner a prueba la teoría (TCL) podríamos, por ejemplo, simular datos no normales, digamos, uniformes (o rectangulares) y para cada triplicado calcular el promedio. Lo que nos dice el TCL es que esos promedios tenderán a la normalidad (a medida que \(n\) aumenta).
Usamos la función
runif(n, min, max) para simular datos uniformesAalicemos esos 1000 promedios de datos uniformes (no normales):
hist(promedios.trplicados.uniformes,
main = 'Histograma de los 1000 promedios de datos no normales')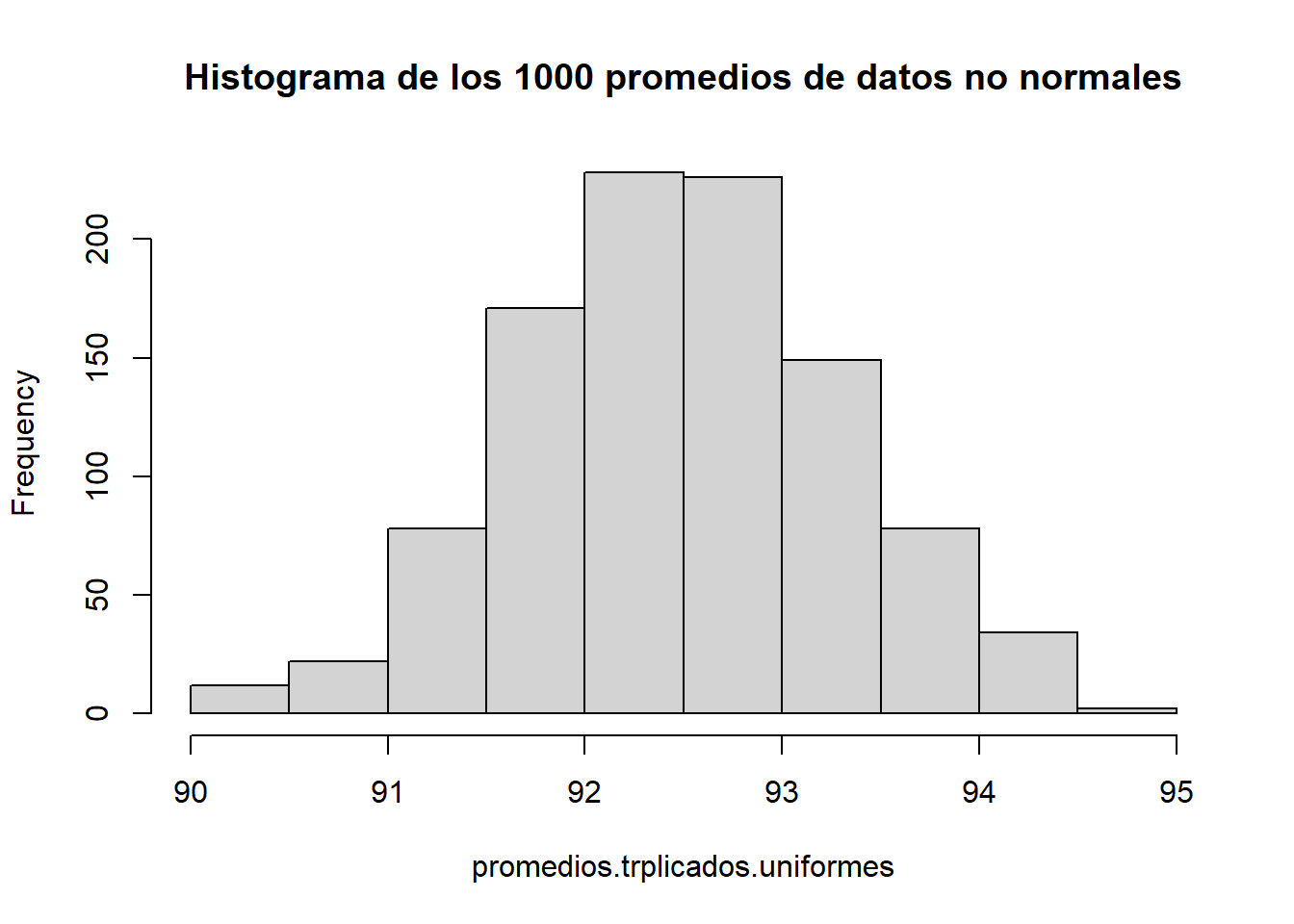
Nuevamente se cumple lo que predice la teoría del TCL: no importa la distribución original de los datos, los promedios tenderán a la Normal (a medida que aumenta el \(N\)).
El TCL nada dice sobre la velocidad de convergencia, ni cuantos \(N\) necesito para “alcanzar” esa normalidad
Por eso utilizo muchas simulaciones en los cursos que dicto. De esa manera podemos evaluar cómo se comporta un método estadístico cuando presentamos datos “no tan perfectos”, por ejemplo:
- Contaminando los datos normales con outliers
- ¿Cuántos outliers puede haber en los datos y aún así obtener un estimador confiable de la media?
- ¿Qué sucede si aplico un test T a datos no normales?¿es aún válida la conclusión?
- me gustaría proponer el rango/4 como una estimación de incertidumbre de medición ¿es un estimador válido?¿qué tan bien se comporta? El rango es \(R = máx - min\), por lo tanto, la porpuesta es de incertidumbre es \(u = R/4\)
- ¿Qué le sucede a la incertidumbre de la curva de calibración si aumento el número de calibrantes?¿y si aumentamos la sensibilidad del instrumento?
- Calcular la incertiudmbre de medición con el Método de Monte Carlo sin asumir que el mensurando (Y) tiene una distribución normal
- etc.
Las opciones son infinitas. La aplicación de simulaciones de datos analíticos es una herramienta muy potente para la Químic@, pues le permite experimentar, tal como si estuviera en el laboratorio, y observar qué esperar de un método estadístico cuando Ud. lo aplica a sus datos reales.
Si quiere aprender más sobre métodos estadísticos avanzados en Química Analítica, puede visitar nuestra página de Cursos y seguirnos en LinkedIn.